Apache PDF box is java based PDF Framework. This framework is developed using Java Technology. Apache PDFBox needs Java version 1.5 or later. Download PDFBox latest version from following link.
|
|
|
https://pdfbox.apache.org/download.cgi
If you want to use PDFBox in Maven based java project, use following Maven dependency in your project.
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>Your version</version>
</dependency>
Following are covered in this Article
Creating a PDF document
Adding images in PDF document
Retrieving content from PDF document
Merging multiple PDF document in Single PDF file
PDDocument document = null;
try {
document = new PDDocument();
PDPage page = new PDPage();
document.addPage(page);
PDFont font = PDType1Font.COURIER;
PDPageContentStream contentStream = new PDPageContentStream(document, page);
contentStream.beginText();
contentStream.setFont(font, 12);
contentStream.newLineAtOffset(100, 700);
contentStream.showText(“This is first PDF Demo.!!! “);
contentStream.endText();
contentStream.close();
document.save(“F:/Suresh/Tech-Blogs/Apache-PDFbox/suresh.pdf”);
document.close();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace ();
}
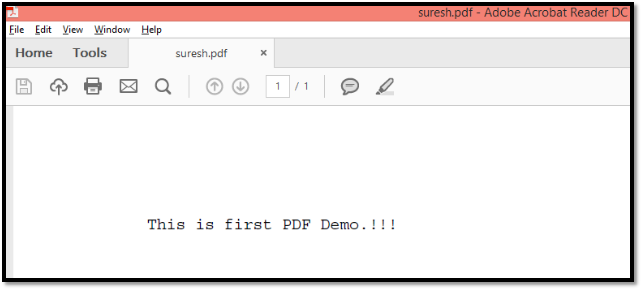
The above code sample creates a PDF document which contains the text information called “This is first PDF Demo.!!!.”Look at below screenshot for the same.
PDPage is representation of particular page from the PDDocument.
PDPageContentStream is an object which used to manipulate the in-memory PDF document i.e. if you want write some content or some text manipulation on the PDDocument , we should use PDPageContentStream object. In the above Program is setting text and font to PDFdocument via PDPageContentStream.
PDDocument document = new PDDocument ();
PDPage page = new PDPage(PDRectangle.A4);
document.addPage(page);
PDFont fontPlain = PDType1Font.TIMES_ROMAN;
PDFont fontBold = PDType1Font.TIMES_BOLD;
PDFont fontItalic = PDType1Font.TIMES_BOLD_ITALIC;
PDPageContentStream pageContentStream = new PDPageContentStream(document, page)
The above program sample shows that how to apply font types and page size for a PDF Document. The PDPageContentStream apply those properties to PDF document by passing document and page value in the constructor.
The above font apply technique must work fine but in certain scenario it doesn’t work because, the font you have used is must installed in your local system otherwise default font apply by PDFBOX framework. If you runs the program in some other system, you need to install the font which used in your local system. To avoid this issue, PDFbox provide a feature to load font TTF file and apply to your PDF text as in below example.
try{
PDDocument document = new PDDocument();
PDPage page = new PDPage();
document.addPage(page);
PDFont font = PDType0Font.load(document, new File(“Yes_Union.ttf”));
PDPageContentStream contentStream = new PDPageContentStream(document, page);
contentStream.beginText();
contentStream.setFont(font, 12);
contentStream.newLineAtOffset(100, 700);
contentStream.showText(“This is the correct way to setting fonts”);
contentStream.endText();
contentStream.close();
document.save(“fontrender.pdf”);
document.close();
}
catch (Exception ex)
{
ex.printStackTrace();
}
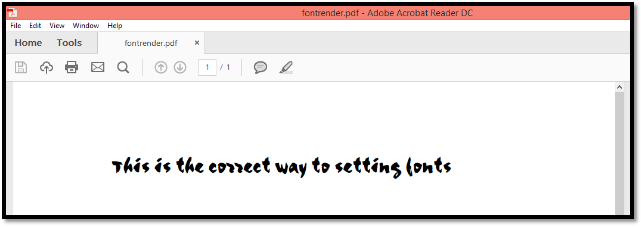
In the above example I am loading a font file called “Yes_Union.ttf”. Whenever execute this program, at runtime PDFBox read the font style and apply to the text. Below is the output of above program.
Below example shows that how to set images and text in the PDF document.
try {
PDDocument document = new PDDocument();
PDPage page = new PDPage(PDRectangle.A4);
document.addPage(page);
PDPageContentStream pageContentStream = new PDPageContentStream(document, page);
PDFont fontBold = PDType1Font.TIMES_BOLD;
pageContentStream.beginText();
pageContentStream.setFont(fontBold, 12);
pageContentStream.newLineAtOffset(100, 550);
pageContentStream.showText(“This is a beautiful flower”);
pageContentStream.newLine();
pageContentStream.endText();
PDImageXObject ximage = PDImageXObject.createFromFile(“flower.jpg”, document);
pageContentStream.drawImage(ximage, 100, 600, ximage.getWidth(), ximage.getHeight());
pageContentStream.close();
document.save(“flower.pdf”);
document.close();
}
catch (IOException ex)
{
ex.printStackTrace();
}
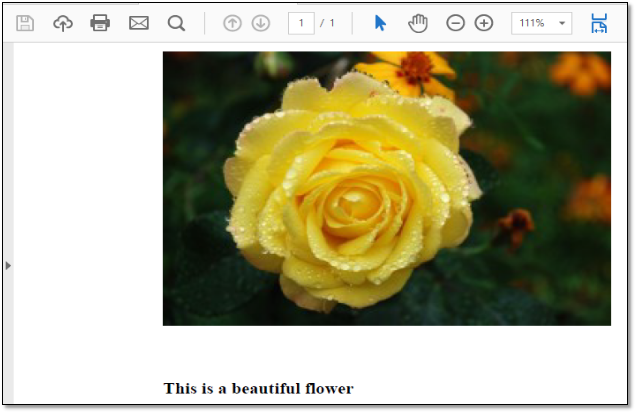
PDImageXObject is used to display the images in the PDF document. Using PDPageContentStream object I am setting text value and displaying images in the pdf document. Below is the screenshot for above program.
Below program shows how to merge the PDF document in single PDF file. This method is as usual like other example like creating new PDF document.
public void createPDFDocument(String fileName,String pageContent) {
PDDocument document = null;
try {
document = new PDDocument();
PDPage page = new PDPage();
document.addPage(page);
PDFont font = PDType1Font.COURIER;
PDPageContentStream contentStream = new PDPageContentStream(document, page);
contentStream.beginText();
contentStream.setFont(font, 12);
contentStream.newLineAtOffset(100, 700);
contentStream.showText(pageContent);
contentStream.endText();
contentStream.close();
document.save(fileName);
document.close();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
This method accepts two parameter, first parameter is filename of pdf document and second parameter is content do you want to display in the pdf document.
public void mergeDocument(String page1, String page2,String pdfFinalFile) {
try{
PDFMergerUtility merger = new PDFMergerUtility();
merger.addSource(page1);
merger.addSource(page2);
OutputStream ouput = new BufferedOutputStream(new FileOutputStream(pdfFinalFile));
merger.setDestinationStream(ouput);
merger.mergeDocuments();
}catch(Exception ex) {
ex.printStackTrace();
}
}
This method is accepts four parameter. First parameter is PDF file name with full path, second parameter is PDF file name with full path and third parameter is new PDF file which is a merged document of PDF page1 and page2 parameter. Third parameter also should have full path with file name. In this method PDFMergerUtility is used for merging multiple file into single file.addSource is a method of PDFMergerUtility which adds the other PDF file in destination PDF file. FileOutputStream Constructor is having the destination pdf file name.
The above two method invoked in main method of java class. createPDFDocument invoked twice and each time it creates a new pdf file called page1.pdf and page2.pdf with different content
public static void main(String[] args)
{
PDFMergeExample pdfMergeExample = new PDFMergeExample();
pdfMergeExample.createPDFDocument(“page1.pdf”, “This is First page demo”);
pdfMergeExample.createPDFDocument(“page2.pdf”, “This is Second page demo”);
pdfMergeExample.mergeDocument(“page1.pdf”,”page2.pdf”,”finaldocument.pdf”);
}
mergeDocument accepts three parameter. First two parameter accepts page1.pdf and page2.pdf. Third parameter accepts new pdf file name which is a merged document of page1.pdf and page2.pdf.
try{
PDDocument pdfDoc =PDDocument.load(new File(“finaldocument.pdf”));
PDFTextStripper pdfTextStripper = new PDFTextStripper();
pdfTextStripper.setStartPage(2);
String content = pdfTextStripper.getText(pdfDoc);
System.out.println(content);
}catch(Exception ex){
ex.printStackTrace();
}
Loading PDF file from physical disk using PDDocument and put into in-memory. PDFTextStripper is a class which used to read the data from PDF document. In the above example setStartPage is used for reading data from page 2. If you want to read full pdf document data, just remove setStartPage method. If you want to read the data from between certain page range use below methods.
pdfTextStripper.setStartPage(2);
pdfTextStripper.setEndPage(4);
The above two line enables the program to read the pdf data between page ranges. According to this program, the API reads the pdf pages from 2nd to 4th page.
Conclusion
This article very useful for who is looking for generating bills, tickets etc. There are many PDF API available in the market but those are not free version we have to pay. There are some few open source PDF API exist but, those are not supported full PDF manipulation functionality. If you use this PDFBox API you can save money from your Project budget and it has rich features to manipulate the PDF.
You can try this tutorial and share your reviews with developers and readers. The post is intended by java web development experts to make you learn about Apache PDFBox.
Equity mutual funds provide a route to maybe greater long-term returns among the varied array…
Did you know that the on-demand services market has grown over 300% in the last…
People had quite a less option for downloading videos earlier as they were not exposed…
720pstream is one of the popular websites that allows the user to stream sports events…
The U.S. Energy Information Administration (EIA) estimates that in 2019, the U.S. residential electricity consumption…
Are you thinking of starting your own business? If so, you should consider forming a Limited…
{kind=link}
{kind=link}
{kind=link}